
Stripe、Anthropic、OpenAIが呼吸器感染症対策の取り組みを支援
Stripe、Anthropic、OpenAIが、呼吸器感染症の予防を目指す新たな研究プロジェクトに資金提供します。
AI&Tech、もう追いかけなくていい。
30秒で読めるニュースダイジェスト
Stripe、Anthropic、OpenAIが、呼吸器感染症の予防を目指す新たな研究プロジェクトに資金提供します。

ゲノム編集技術Crisprの発明者が、AIが科学的発見における人間の努力を代替することに懐疑的な見解を示し…

AIモデルが利用できるウェブデータの収集と構造化を支援する新しいインフラ層が登場しています。

ウェドブッシュ証券のアナリストが、マイクロン・テクノロジーの決算が市場にとって重要な局面になると指…

PangramのCEOが、言語モデルは同じ議論を繰り返す傾向があり、人間との違いが明らかになると述べました。
富士通がGPU効率を最大475倍向上させるLLMアーキテクチャ「PHOTON」を開発しました。

アブダビのMGXが、地域および世界の投資家から約500億ドルのAI特化型ファンドを設立しました。

JPモルガンのアナリストが、AI関連の設備投資が今後も継続するとの見解を示しました。
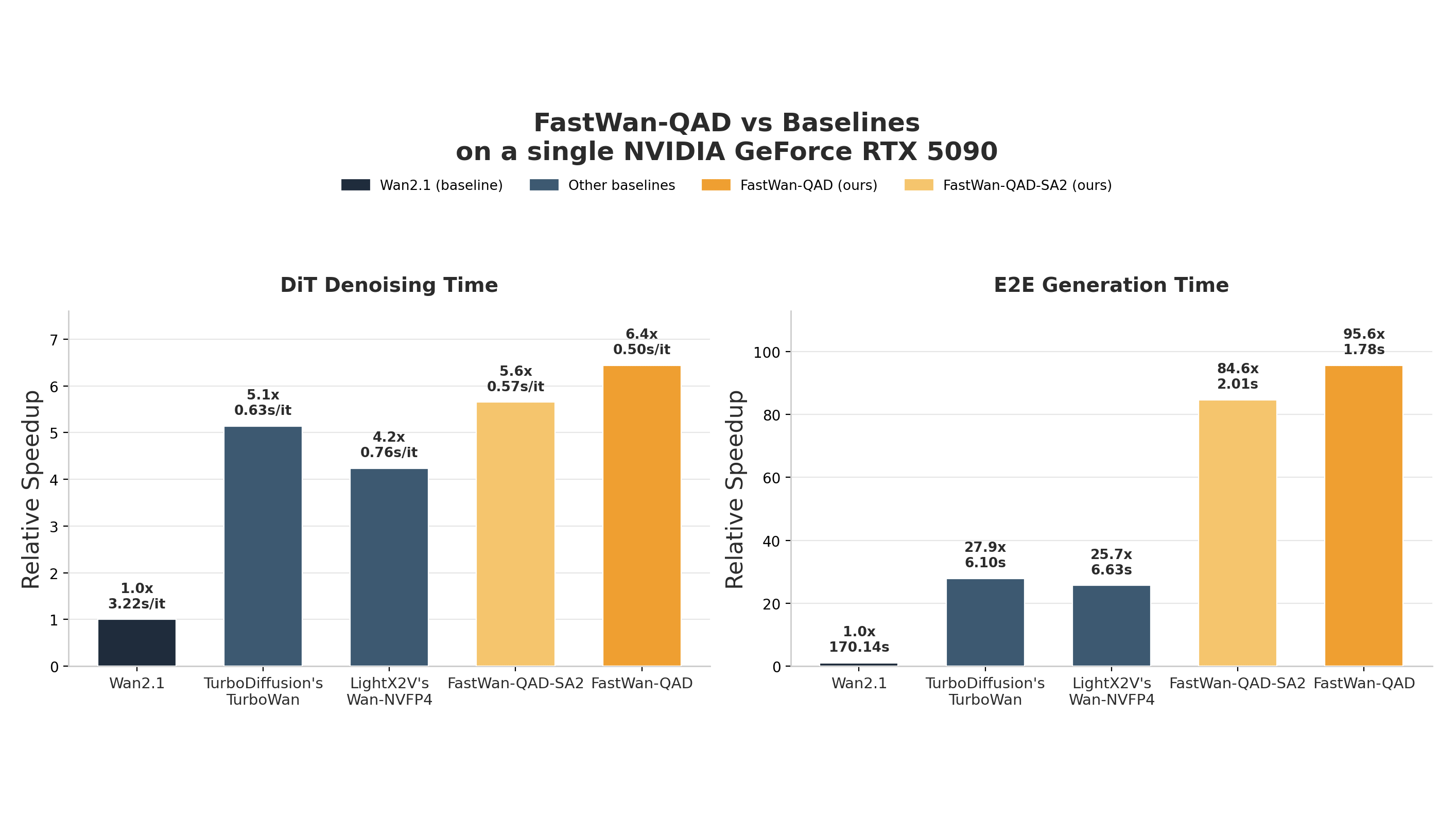
動画生成AIモデル「FastWan-QAD」が発表され、RTX 5090で5秒動画を1.8秒で生成可能です。

フランスのスタートアップが、神経の治癒を助ける生分解性ポリマーを開発しました。

ソフトバンクグループの孫正義氏がAIバブル論を一蹴し、AI革命の初期段階にあると強調しました。
JD.comのチーフエコノミストが、AIが牽引する中国経済の展望を語りました。