
Google、Gemini搭載AIホームスピーカーを6月25日発売
GoogleがGemini AIプラットフォームを深く統合した新しいホームスピーカーを6月25日に発売します。
AI&Tech、もう追いかけなくていい。
30秒で読めるニュースダイジェスト
GoogleがGemini AIプラットフォームを深く統合した新しいホームスピーカーを6月25日に発売します。

GoogleがGeminiチャットボットを搭載した新型スマートスピーカーを発表しました。

GoogleがGeminiベースの新型スマートスピーカー「Google Home スピーカー」を1万6500円で発売します。

Pinterestが会話型AIを活用した実験的なショッピングアプリ「Ask Pinterest」をリリースしました。
OpenAIとMolecule.oneが、GPT-5.4を活用したAI化学者が医薬品製造の重要な反応を改善したことを発表しまし…

GLM-5.2は、長期間にわたる複雑なタスク処理に特化した大規模言語モデルです。
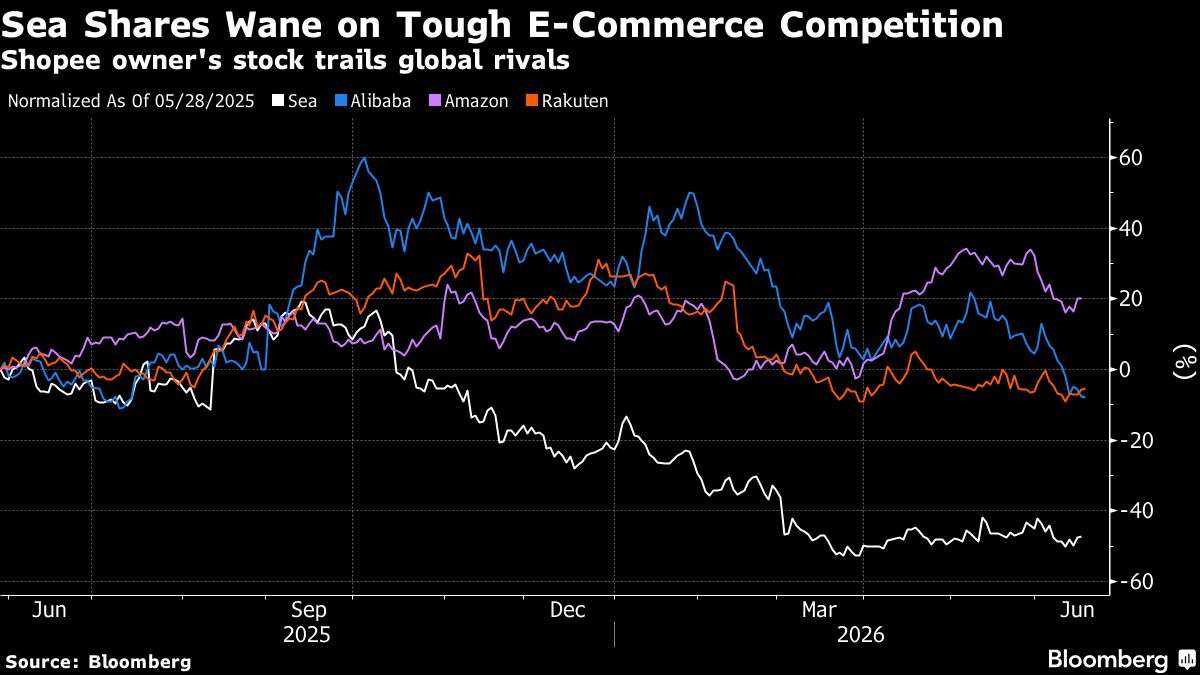
シンガポールのインターネット企業Sea社が、生成AIチャットボット「Migoo」を米国を含む地域で展開し、AI…
OpenAI共同創業者が、巨大AIモデルのアップデート作業の困難さとデータ重要性を語りました。
AnthropicがAIコーディングアシスタント「Claude Code」のユーザーと利用用途に関する分析結果を公開しま…
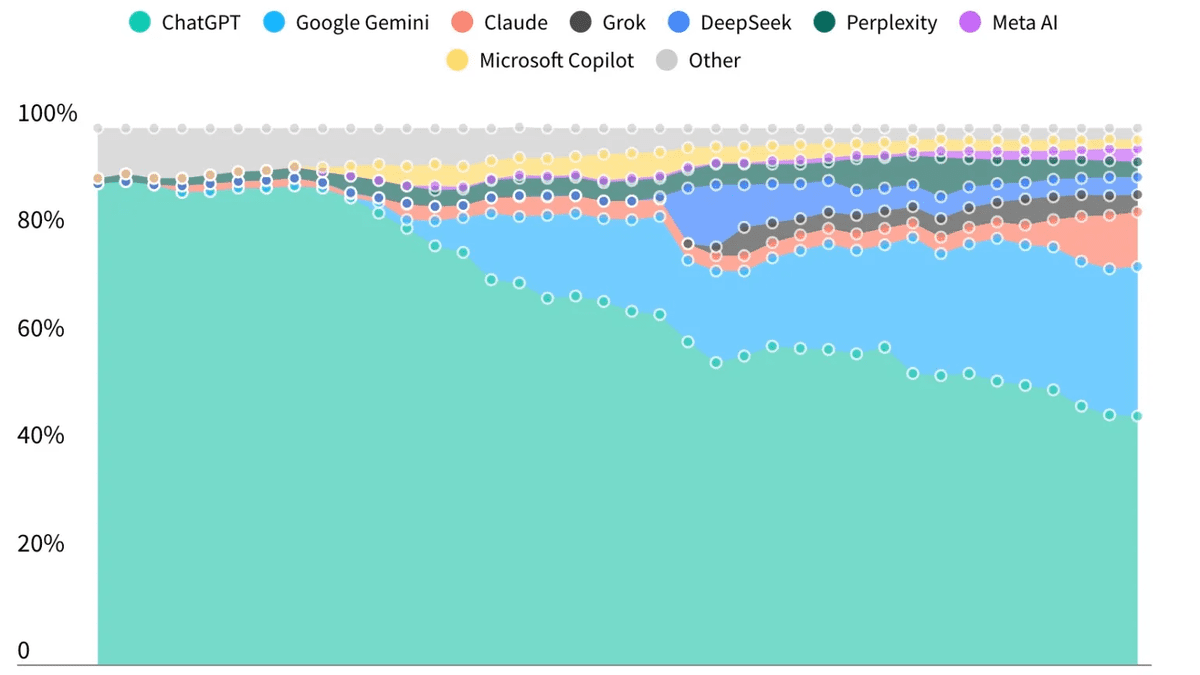
ChatGPTの利用者シェアが初めて50%を割り込み、GeminiやClaudeが追い上げを見せています。
日立がOpenAIと連携し、AIモデル「Codex」を活用したレガシーシステム刷新とサイバー防衛を本格化します。

東北大学の赤間准教授が日本語の文化的ニュアンスを理解・生成する自然言語処理の研究について語りました。