ゲーリー・ゲンスラー元SEC委員長、AIは現代で最も変革的な技術と発言
ゲーリー・ゲンスラー元SEC委員長が、AIは現代で最も変革的な技術であると述べました。
AI&Tech、もう追いかけなくていい。
30秒で読めるニュースダイジェスト
ゲーリー・ゲンスラー元SEC委員長が、AIは現代で最も変革的な技術であると述べました。

初期のAnthropic支援企業であるメンロー・ベンチャーズが、過去最大となる30億ドルの資金調達に成功しまし…
Cursorが初の自社開発AIモデルと、新しいGitプラットフォーム、モバイルアプリを発表しました。
OpenAIが、企業向けにAIが自律的にコードを改善する「Meta-Harness R&D」を発表しました。
OpenAIがサイバーセキュリティ向け新モデル「GPT-5.5-Cyber」を発表し、既存モデルを上回る性能を示しまし…
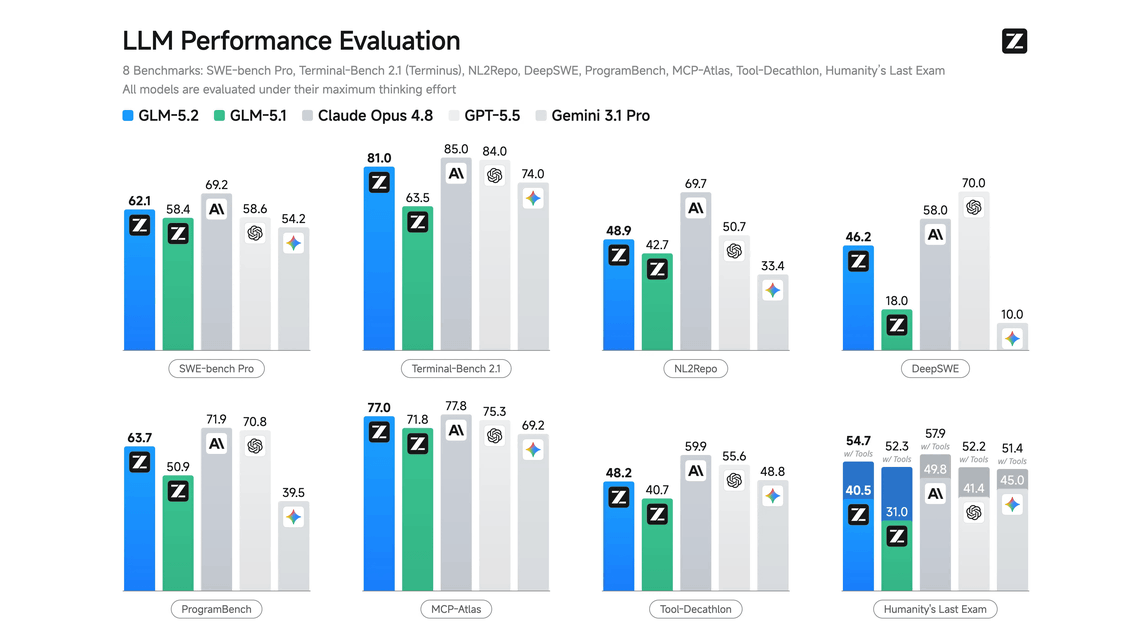
OpenRouterで中国製AIモデル「GLM-5.2」のAPI利用者が急増しました。
アリアンツのCIOが、市場はAIによる淘汰効果をすでに価格に織り込んでいると述べました。

NVIDIAが複数の写真から高品質な3Dシーンを生成するAIモデル「ArtiFixer」を発表しました。

OpenAIがサイバーセキュリティに特化したAI「Daybreak」の提供を拡大すると発表しました。

OpenAIとAnthropicが業務現場支援を強化し、日本のSIerビジネスへの影響が分析されました。

トヨタファイナンスが顧客問い合わせ対応にAIエージェントとRPAの併用システムを導入しました。

AIが自然言語の指示に基づき3Dモデルを生成する技術の現状が紹介されました。