
OpenAIがAIのコーディング能力を測る代表的ベンチマークは「もはや無意味」と説明、初期の解けなかった問題を調べると逆に問題が悪いことが発覚
OpenAIがAIコーディング能力の代表的ベンチマーク「SWE-bench Verified」がもはや無意味だと発表しました。
AI&Tech、もう追いかけなくていい。
30秒で読めるニュースダイジェスト
OpenAIがAIコーディング能力の代表的ベンチマーク「SWE-bench Verified」がもはや無意味だと発表しました。

ゴールドマン・サックス香港の従業員が、AIエージェント「AnthropicのClaude」へのアクセスを失いました。
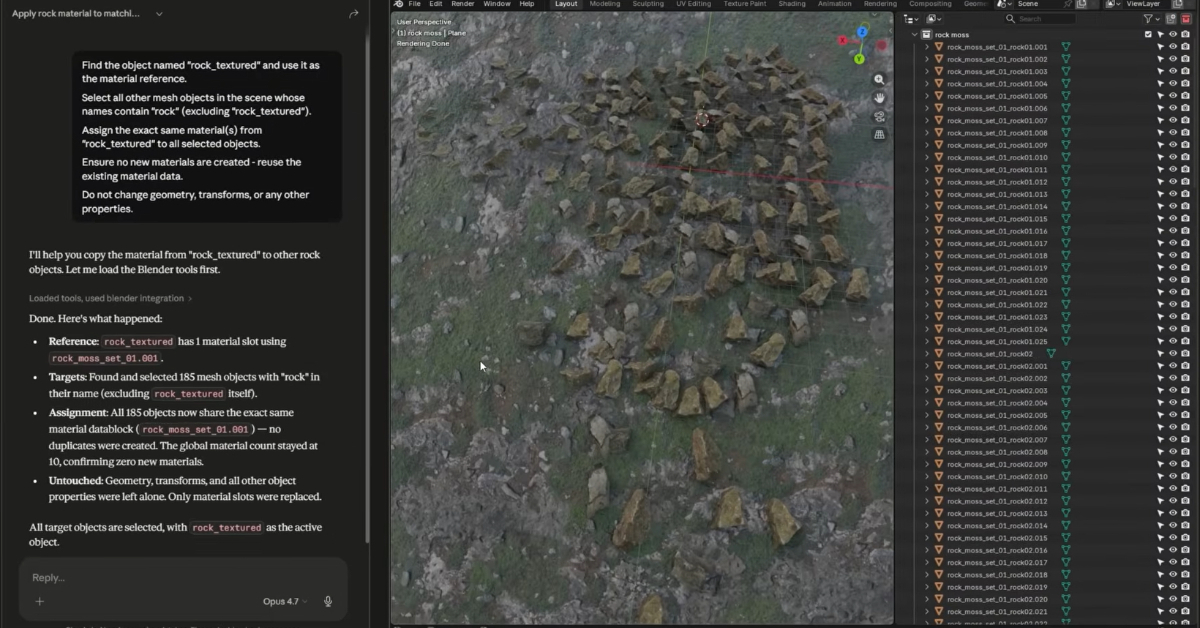
AnthropicがClaudeとBlenderやPhotoshopを連携させる8種類のクリエイティブ系コネクタを公開しました。

MicrosoftがOpenAIへの独占的な投資権を手放し、AI競争における今後の戦略が注目されています。

OpenAIに関する報道が市場の不安を煽り、株価が下落しました。

米国のAIスタートアップPoolsideが、無料かつ高性能なオープンモデル「Laguna XS.2」を公開しました。

OpenAIが売上とユーザー目標を達成できなかったとの報道を受け、関連企業の株価が下落しました。

OpenAIは、売上成長に関する懸念報道に対し、消費者および企業向けビジネスが好調であると反論しました。

Amazonが、Microsoftの独占契約終了に伴い、OpenAIのAIモデルをクラウド顧客に提供開始します。

NVIDIAが、ビジョン・音声・言語を統合したオープンなマルチモーダルAIモデル「Nemotron 3 Nano Omni」を…

NVIDIAが文書、音声、動画を理解するマルチモーダルAIモデル「Nemotron 3 Nano Omni」を発表しました。
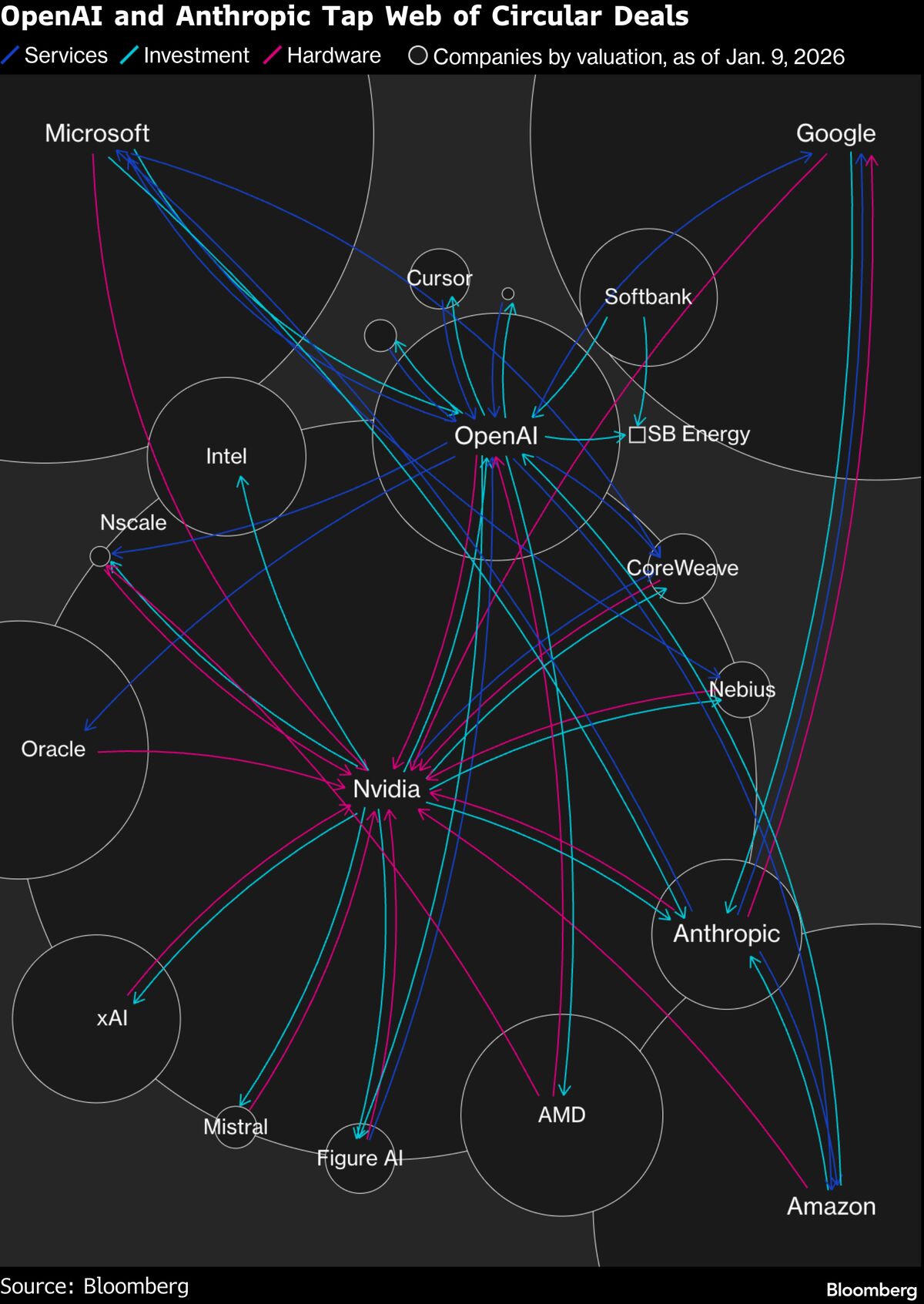
OpenAIが、売上成長に関する懸念報道に対し、消費者および企業向け事業が好調だと反論しました。